
Over the summer I was lucky enough to speak at Karta conference in Frankfurt. I presented a lightning talk on CI/CD followed by a workshop called ‘Get to production!’. The goal of the talk and workshop was to cover the pipeline basics and for the group to have the opportunity to create and deploy a simple application using pipelines as code.
So, what is a CI/CD pipeline?
Well, its a tool to automate the software delivery process; It initiates code builds, runs automated tests and deploys code.
Ideally we deploy a single code change with a single artifact over a single run of our pipeline- promoting the same artifact, deploying to many environments during the process.
We use them so that we can reduce the cost of deployments, remove manual errors, provide standardized feedback loops and enable product iterations. By keeping our batch size small and automating the entire process on each code change we can reduce risk.
We can reduce risk even further by adhering to best practice.
We should aim to
Aim for the fastest feedback
It sucks waiting ages for a build to only find that you’ve broken a styling rule. We are aiming to get the best possible flow rate out of our pipeline, and when creating one for our application we should keep this in mind.
We can layout our pipeline to have
- Fast automated tasks as soon as possible.
- Manual tasks as far to the right as possible- allow as much automation as possible before a person needs to get involved
- Aim to remove manual tasks if they do not provide value.
- Fan out stages. Our pipeline states that we can only run a stage if the previous stage has passed. If the previous stage does not actually need to pass for us to start the next stage we should consider fanning out our stages and allow them to run together. There are some considerations here though, we may see expensive spikes in resources during these fan out stages. The increase in performance may come with a fiscal cost.
Build packages once
We want to be sure the thing we’re deploying is the same thing we’ve tested throughout the deployment pipeline, eliminating the packages as the source of the failure.
Deploy the same way to every environment
We test the deployment process many times before it gets to production,eliminating the deployment process as the source of any problems.
Smoke test your deployments
Make sure your application is running and available as part of the deployment process, checking the application is functional gives us quick feedback before running more expensive tests.
This can be a simple ping or a small set of user journey tests.
Keep your environments similar
When possible this includes the same version of the operating system and middleware packages, configured in the same way. This has become much easier to achieve with modern virtualization, container technology and infrastructure as code.
We can trigger by
We have a few methods of triggering stages within a pipeline or a pipeline itself.
Code commit
Each change in code triggers an automated build-and-test sequence for the given project, providing feedback to the engineering team. If we follow trunk based development (or short lived branches) we get feedback on how our change will work with the latest version of the application often.
Scheduled/ CRON
These are particularly useful when factors outside the code may have an impact on your application. Vulnerability scanning is a good use case, especially in codebases with a low churn rate, if we only scan for vulnerabilities in our code commit triggered pipeline we would need to wait for a change to the repository before finding out that our package contains a security risk.
Manual
In some situations a manual triggered pipeline or stage may be necessary, you may require sign-off from QA or have set release dates. Its useful to know that any manual gate could become a bottleneck, by pushing manual gates as far to the right as possible we can increase the flow rate of our pipeline. Better yet, removing the manual gates altogether.
The workshop
The goal of the workshop was to take an application and build our own pipeline using pipelines as code. All the other bits that came with the workshop simply enabled the application to run and to be deployed, however I wanted these to be as readable and simple as possible.
We focused on:
- Circle CI
- VueJS
- Heroku
However we also used:
- Babel
- Cypress
- Mocha
- NPM
- Docker
- GitHub
We first validated that everyone had all the tools for the workshop
vue --version
heroku --version
git --version
docker --version
node --version
npm --version
curl --version
Then we forked and cloned the repo
We then followed the project on CircleCI
And generated a token
At this point everyone should have all the dependencies required, the accounts setup and our basic pipeline running.
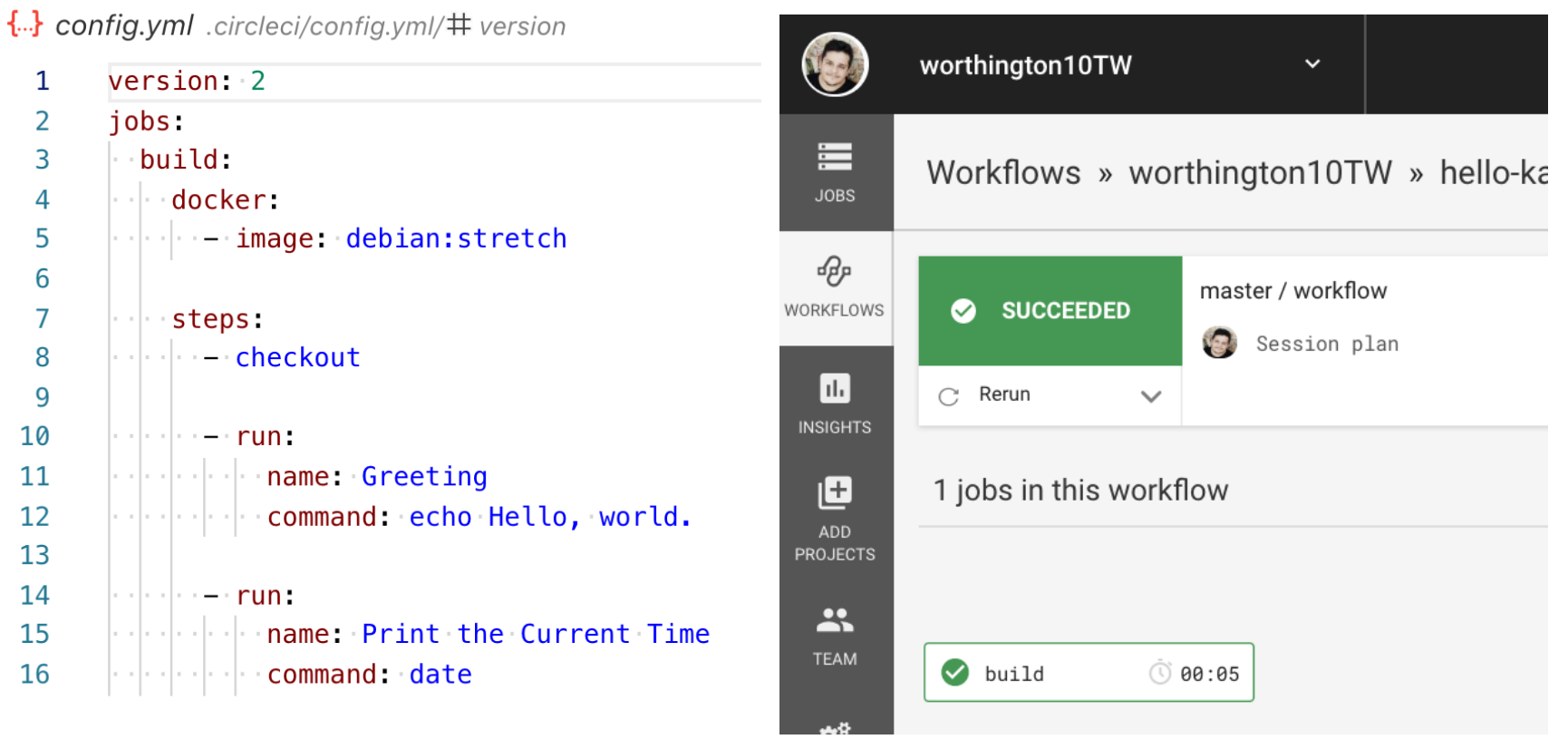
The code provided contained a script to get us up and running, this script created a heroku application and added the relevant environment variables to circleCI.
The repository also contained a .vue folder that allowed the vue CLI to create the same application for everyone in the workshop by running vue create --preset ./hello-karta/.vue hello-karta.
We also had a Dockerfile that runs the application, a basic pipeline that spits out today’s date (but does nothing with the code), and a couple of scripts (One to deploy the application and another to ping the application).
We could then start building our
Path to production
Build

Build might not be the greatest name for this stage, and there is an argument to say that this stage isnt actually necessary. The workshop was designed to be language agnostic and show a possible path to prod of an application, this stage simply installed the dependencies.
We introduced the concept of caching. By caching our node_modules folder we reduce the need for pulling down all the dependencies on every stage that needs them, we can use the package-lock.json to ensure that the cache is broken when the dependencies have changed.
Code quality gate

We then ran a simple code quality gate, these are usually pretty quick and ensure fast feedback.
Test automation

We then can fan-out. We run our application unit tests, whilst at the same time running our much more expensive e2e cypress tests.
Publish

We can now create our deployable application.
Deploy to staging

Deploying our artifact to our staging environment using the script provided.
Smoke tests and E2E tests
We then ping our application to make sure its up and run our Cypress suite against the newly deployed application.
Manual approval

We then have a our manual gate. Our application does not currently have the ability to hide features not ready for release using feature toggles. Therefore to ensure that the decision to release a feature still remains a business decision and not a technical one we implement a manual approval stage.
Deploy to prod

We then deploy the same artifact that we deployed to staging to production, using the same script and deployment method.
Check our application works

We finally check our application is up and running in the same way we checked that staging was up and running, using the same ping script.
Our workflow
workflows:
version: 2
build_and_test:
jobs:
- build
- code-quality:
requires:
- build
- unit-test:
requires:
- code-quality
- e2e-test:
requires:
- code-quality
- publish:
requires:
- unit-test
- e2e-test
- deploy-to-staging:
filters:
branches:
only:
- complete
requires:
- publish
- staging-e2e:
requires:
- deploy-to-staging
- approve-release:
type: approval
filters:
branches:
only:
- complete
requires:
- staging-e2e
- deploy-to-production:
filters:
branches:
only:
- complete
requires:
- approve-release
- ping:
requires:
- deploy-to-production
And thats our path to production. To recap we created a VueJS application with Mocha unit tests and Cypress E2E tests, using CircleCI and pipelines as code to install, lint, test and deploy our application. Our application is deployed to Heroku and served using docker over multiple environments.
The deck from the talk can be found here (Recently migrated from gitpitch to hackmd)
Get the code